When Google Maps was first released in Feb 2005, it was pretty mindblowing for most web users (and even developers), simply because no one had ever seen such a richly interactive web page. That sort of interactivity was the exclusive domain of native applications, and while GMail had been released nearly a year earlier (on Apr 1 2004), the dynamic scrolling, zooming, and rendering felt like entirely a different level of interactivity.
Feb 2005 • Mapping Google #
By now, many of you will have gone and tried out the new Google Maps application. By and large, you have to admit that it’s pretty damned slick for a DHTML web application – even my wife was impressed, and that’s not easy with geek toys. So, in the spirit of Google Suggest and GMail, I’ve decided to have a quick peek under the hood to figure out what makes it tick.
Not quite like GMail #
The first thing I noticed is that it doesn’t quite work like GMail. Whereas GMail uses XMLHttp to make calls back to the server, Google Maps uses a hidden IFrame. Each method has its benefits, as I’ll discuss below, but this difference of approach does seem to imply that it may not be the same team doing the work.
The Graphics #
Probably the most striking thing about Google Maps is the very impressive (for DHTML, anyway) graphics. Now, I’m sure that many of you old JavaScript hacks out there have known this sort of thing was possible for a long time, but it’s very cool to see it (a) actually being used for something real, and (b) where normal users will see it.
For those to whom the implementation is less than obvious, here’s a quick breakdown. The top and side bars are (more or less) simply HTML. The center pane with the map, however, is a different beast. First, let’s address the map itself. It is broken up into a grid of 128x128 images (basically like an old tile-based scrolling console game). The dragging code is nothing new, but the cool trick here is that each of these images is absolutely positioned – and the ‘infinite’ scrolling effect is achieved by picking up tiles that are off-screen on one end and placing them down on the other end. The effect is kind of like laying track for a train by picking up track from behind it.
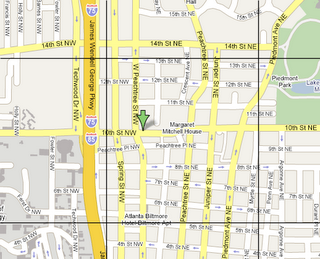
Google map, with tiles outlined
The push-pins and info-popups are a different matter. Simply placing them is no big trick; an absolutely-positioned transparent GIF does the trick nicely. The shadows, however, are a different matter. They are PNGs with 8-bit alpha channels. Personally, I didn’t even realize you could depend upon the browser to render these correctly, but apparently (at least with IE6 and Mozilla), you can. And they actually render pretty quickly – for proof, check out the overlaid route image (at the end of the article), which is often as big as the entire map view.

The pushpin, with its two images outlined
Communicating with the Server #
There are two ways in which Google Maps has to communicate with the server. The first is to get map images, and the second is to get search results. It turns out that getting map images is remarkably easy – all you have to do is set an image tile’s URL. Because the coordinate system is known and fixed (each tile represents a known area specified in longitude and latitude, at a given zoom level), the client has all the information it needs to set tile URLs. Each tile URL is of the following form:
http://mt.google.com/mt?v=.1&x={x tile index}&{y tile index}=2&zoom={zoom level}
I’m not sure what the ‘v’ argument specifies, but it never seems to change. The others are fairly self-explanatory. One nice side effect of this is that the images have fixed URLs for a given chunk of the earth’s surface, so they get cached. If you’re doing most of your searches in one region, then the app can be quite snappy once everything gets cached.
Doing searches is another matter. Clearly, you can’t ‘submit’ the entire page, because that would destroy your map and other context. Google’s solution is to submit a hidden IFrame, then gather the search results from it. Let’s say, for example, that you simply wanted to go to Atlanta. You type ‘Atlanta’ in the search area, and the following HTTP GET is made:
http://maps.google.com/maps?q=atlanta&z=13&sll=37.062500%2C-95.677068&sspn=37.062500%2C80.511950&output=js
There are a couple of things to notice here. The ‘question’ is passed in the ‘q’ parameter (much like Google). The other arguments are ‘z’ for zoom, ‘sll’ for longitude & latitude (your current focus, I believe), and ‘sspn’ to specify the span/size of your viewing area. What’s interesting is what comes back:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="content-type" content="text/html; charset=UTF-8"/>
<title>Google Maps - atlanta</title>
<script type="text/javascript">
//<![CDATA[
function load() {
if (window.parent && window.parent._load) {
window.parent._load({big chunk of XML}, window.document);
}
}
//]]>
</script>
</head>
<body onload="load()">
<input id="zoom" type="text" value=""/>
<input id="centerlat" type="text" value=""/>
<input id="centerlng" type="text" value=""/>
</body>
</html>
This HTML is loaded into the hidden IFrame which, when loaded, will punt a big chunk of XML back up to the outer frame’s _load() function. This is kind of a cool trick, because it saves the outer frame from having to determine when the IFrame is done loading.
I mentioned before that there was some advantage to be had by using a hidden IFrame over making direct XMLHttp requests. One of these is that the IFrame’s state affects the back button. So every time you do a search, it creates a new history entry. This creates an excellent user experience, because pressing the back button always takes you back to the last major action you performed (and the forward button works just as well).
Big Hunks of XML #
Ok, so now the outer frame’s code has a big chunk of XMl. What can it do with that? Well, it turns out that Google Maps depends upon two built-in browser components: XMLHttpRequest and XSLTProcessor. Oddly enough, even though it doesn’t use XMLHttpRequest for making calls to the server, it does use it for parsing XML. I’ll get to the XSLT later.
Here’s an example of the XML response that comes back from the ‘Atlanta’ request above:
<?xml version="1.0"?>
<page>
<title>atlanta</title>
<query>atlanta</query>
<center lat="33.748889" lng="-84.388056"/>
<span lat="0.089988" lng="0.108228"/>
<overlay panelStyle="/mapfiles/geocodepanel.xsl">
<location infoStyle="/mapfiles/geocodeinfo.xsl" id="A">
<point lat="33.748889" lng="-84.388056"/>
<icon class="noicon"/>
<info>
<title xml:space="preserve"></title>
<address>
<line>Atlanta, GA</line>
</address>
</info>
</location>
</overlay>
</page>
Nothing surprising here – we have a title, query, center & span, and the location and name of the search result. For a slightly more interesting case, let’s look at the response when searching for ‘pizza in atlanta’:
<pre>
<?xml version="1.0" ?>
<page>
<title>pizza in atlanta</title>
<query>pizza in atlanta</query>
<center lat="33.748888" lng="-84.388056" />
<span lat="0.016622" lng="0.017714" />
<overlay panelStyle="/mapfiles/localpanel.xsl">
<location infoStyle="/mapfiles/localinfo.xsl" id="A">
<point lat="33.752099" lng="-84.391900" />
<icon image="/mapfiles/markerA.png" class="local" />
<info>
<title xml:space="preserve">
Kentucky Fried Chicken/Taco Bell/<b>Pizza</b> Hut
</title>
<address>
<line>87 Peachtree St SW</line>
<line>Atlanta, GA 30303</line>
</address>
<phone>(404) 658-1532</phone>
<distance>0.3 mi NW</distance>
<description>
<references count="9">
<reference>
<url>http://www.metroatlantayellowpages.com/pizzaatlanta.htm</url>
<domain>metroatlantayellowpages.com</domain>
<title xml:space="preserve">Atlanta<b>Pizza</b> Guide-Alphabetical Listings of Atlanta<b>...</b></title>
</reference>
</references>
</description>
<url>http://local.google.com/local?q=pizza&near=atlanta&latlng=33748889,-84388056,11825991348281990841</url>
</info>
</location>
{ lots more locations... }
</overlay>
</page>
Again, nothing too surprising when you think about the data that’s going to show in the map pane. But how do the results get shown in the search result area to the right? This is where things get a little wacky. The JavaScript actually uses the XSLTProcessor component I mentioned earlier to apply an XSLT to the result XML. This generates HTML which is then shown in the right panel. We’ve come to expect this sort of thing on the server, but this is the first time I’ve ever seen it done on the client (I’m sure it saves Google lots of cycles, but personally I didn’t even know XSLTProcessor existed!)
Driving Directions #
There’s one last case to discuss, and that’s driving directions. This works
just like other searches, including XSLT to show the results, with one
exception: the result XML includes a
<polyline numLevels="4" zoomFactor="32">
<points>k`dmEv`naOdGC??EtD??@|DAxL??hEFjJ@ ...</points>
<levels>BBB???BB?BB??@??@?????BB??@?????@? ...</levels>
</polyline>
This polyline data is then used to request the route PNG from the server using a URL like so:
http://www.google.com/maplinedraw?width=324&height=564&path=sRS?k@fB@?}As@e@CGAIA}@BwCEu@Bs@?E_@cACS@a@PaC ...
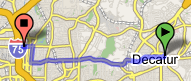
The route overlay
In Summary #
That’s about it. I hope that demystifies this application a bit; the real magic, of course, is all the work going on to enable this on the back-end. The fact that Google’s servers can handle all of these images requests, route finding, line drawing, searches and the like so quickly is the real magic. I also want to point out that their map renderer (or the one they purchased) works much better than all the other ones I’ve seen on Mapquest, Mapblast, and the like. That alone makes it worth using, if only so you can actually read the map!
I also think it bears noting that Google is pulling out all the stops to build rich web apps, no matter how weirdly they have to hack the browser to make them go. And I strongly believe that this is a trend that is here to stay – XHTML Strict/CSS/etc be damned. At the end of the day, what really matters to users is compelling apps that let them get their work done quickly.
Feb 2005 • More Fun with Maps #
Well, that was certainly an unexpected flood of responses. Apparently I wasn’t the only one that found Google Maps interesting &emdash; I was amazed at some of the creative hacks that some commentors created. After sifting through this deluge, I decided to summarize some of the findings, clarify a few points, and add a few other comments on implementation details. This is kind of a grab bag of points, so please bear with me.
Cut Google some slack on Safari #
I noticed a lot of people complaining both here and on Slashdot about the lack of Safari support. And I’m not completely unsympathetic, as I’m running a shiny new Mac Mini at home that I love. However, as anyone can attest that has ever tried to build an even remotely complex web application, it just ain’t easy. And please don’t blather on about who implements ‘web standards’ better &emdash; no one really implements them, and even if they did, you’d still be outta-luck if you wanted to do anything interesting in DHTML.
If you take some time to dig through Google’s Javascript, you’ll find that there is proto-Safari support all over the place. They’re clearly working on it, and you really can’t ask for much more than that.
The route overlay #
There’s one really interesting facet of the route display that I totally failed to notice the first time around &emdash; I was doing everything in Mozilla and simply didn’t notice that they were actually using Microsoft’s VML to render the route on IE. It may be non-standard, but you have to admit that it’s very fast and effective! And switching off between client-side and server-side rendering in one code base is a pretty cool hack.
Decoding polylines and levels #
Also because I only noticed the server-side route rendering the first time
around, I failed to check whether the route’s polylines were being decoded on
the client. Well, as several commentors pointed out, they are. In fact, the
decoding loop is fairly simple (just have a look at decodePolyline() for the
details). I originally assumed this stream was encoded so that you could just
grab it and send it back to the server for rendering (thus making the image
server stateless, and the rendered route cacheable). However, since they’re
decoded on the client, it appears that it also served the purpose of keeping
the size reasonable &emdash; encoding all those points as XML would get pretty
fat.
I also glossed over the fact that there’s another stream associated with the route called ’levels’. This is an interesting trick that allowed them to encode the route points at different zoom levels in the same stream (because there’s really no opportunity to easily go back to the server for a new route when you change zoom levels &emdash; when you’re rendering on the client).
Flow of control for form submit and IFrame #
Although it’s something of a wacky implementation detail, it’s interesting to
note how the search form at the top of the application works. It is actually
contained in a FORM element, although it has three separate DIVs whose
visibilities are swapped as you click on the different search links. However,
it can’t be submitted directly, as that would cause the entire application to
reload. Instead, the event handler for the form’s submit button suppresses the
reload, gathers the search parameters, and calls the application’s search()
method. This method builds a query URL and sets a hidden IFrame’s ‘src’
parameter, which causes it to gather a new chunk of XML from the server.
As I believe I mentioned in the previous article, requesting the XML via this IFrame has the additional benefit that it ties the browser’s history perfectly to the application’s state. Although it would be nice if someone would fix Mozilla such that the history titles are correct (this works properly in IE).
asynchronousTransform()
#
It turns out that Google Maps communicates with the server both through the hidden IFrame and the XMLHttpRequest object. I mentioned in the last article that it transforms the downloaded XML using XSL. Well, that XSL is not actually hard-coded into the application. Instead, whenever it needs to perform a transform, it requests the XSL via XMLHttpRequest, performs the transform, and caches the XSL itself so that it won’t need to download it again.
Permalink and feedback #
One of the potential downsides to building an application that runs entirely within a single page is that the address bar never changes, so it’s not possible for the user to create links to the application’s current state. Of course, many ’normal’ web applications don’t really work properly when you try to link to their internal pages, but people have still come to expect it to work most of the time.
Google’s solution to this problem was to create the ’link to this page’ anchor in the right panel. When you click on it, it refreshes the entire application with a URL that encodes the entire application state. Pretty nifty, as it gives you the important parts of the behavior everyone likes to call ‘REST’ without having to break the application up into a million little pieces.
You may have noticed that the ‘feedback’ link also encodes the application’s state. The map application actually updates the hrefs of both of the stateful links every time the application state changes.
Profiler #
Often you can tell quite a bit from code that is left lying around unexecuted. In this case, it appears that the Google Maps team may have had performance problems in some methods (or may simply have been trying to head them off). You can tell this because there are some prologue/epilogue functions being called in various methods that definitely smell like a hand-rolled profiler. And if you look at the list of methods that contain these hooks, it definitely makes sense:
Polyline.decodePolyline()
Polyline.decodeLevels()
Polyline.getVectors()
Page.loadFromXML()
Map.getVMLPathString()
Map.createRawVML()
Map.createVectorSegments()
Map.createImageSegments()
Map.drawDirections()
If this is indeed the case, I think it’s worth noting that Mozilla’s profiler actually does a reasonably good job. And although performance on one browser is not perfectly indicative of performance on the others, the Mozilla results have been roughly indicative of results on IE in my experience.
Tiles & longitude/latitude mapping #
The mapping of tiles to longitude/latitude pairs is relatively straightforward.
The code for doing transformations in both directions can be found in the
functions getBitmapCoordinate(), getTileCoordinate(), and getLatLng(), and
several commentors have picked apart the transforms in more detail. As
mentioned before, the tiles’ image source URLs encode the longitude, latitude,
and zoom level.
Several commentors also suggested that the entire map was pre-rendered at every zoom level, so that the web server could simply deliver the tiles without further consideration. While I believe this is partially true, I also am fairly certain that some areas will be viewed far more often than others. Clearly, Google is working from vector data at some level, and it would probably make far more sense to render tiles on the fly and caching them. This would also make a big difference when it came to dealing with updates to the vector data, especially if those updates could be localized such that the entire tile cache need not be invalidated.
Crazy ‘bookmarklet’ #
Finally, I have to give kudos to those who’ve been working on the ‘bookmarklet’ that reaches into the running application and makes it dance. It’s completely novel to me that you can add bookmarks of the form ‘javascript:’ and have them run in the context of the current page. It makes perfect sense, of course &emdash; I just never thought of it. It appears that the current state of the art of this hack can be found here.
The only unfortunate part about this (through no fault of the authors’) is that it’s likely to be brittle in the face of updates to Google Maps &emdash; the Javascript has to reach into global variables within the running application, which will probably change when Google’s code obfuscator is run. It does give us a glimpse of a possible future, however, when even web pages publish public API’s for developers to use. Very interesting!
Feb 2005 • Making the Back Button Dance #
It seems that I keep discovering nifty things about Google Maps. I didn’t notice anyone commenting on the details of the way it interacts with the browser history, but there’s one really groovy trick it plays that really adds to usability.We already know that clicking the back button causes it to display the results of your previous search. That’s certainly helpful, as you don’t lose your search history. If you play with it a bit, however, you may also notice that it also moves the map to your previous search location as well. This applies to all of your search history, as you move forwards and backwards amongst your results. Try it out.
But how? #
If you dig through the DOM a bit (e.g. using Mozilla’s DOM Inspector), you will see that there are three input fields in the hidden IFrame that the application uses to communicate with the server. At first glance, it doesn’t appear that they’re used for much of anything (I myself first dismissed them as an unfinished attempt to make the application state easily to link to). If you look at the application code, you’ll see that it stores the current map state (latitude, longitude, and zoom level) in these fields every time it changes.
Here’s the tricky part. When a search result comes back from the server, the HTML in which it’s wrapped contains yet another set of three empty fields. When you click back, though, the browser replaces the IFrame contents with its previous state, including the values that were stored in these fields. You’ve probably seen this before in regular web applications, when the browser tries to maintain the state of forms when it goes back to a cached version.
So you’ve clicked the back button, the hidden IFrame contains its previous state, and the right panel now displays your previous search results. The application also reaches into these three fields to get the previous map state, and pans/zooms as necessary to display the map in its previous state as well (you’ll find the code that does this in the application’s loadVPage() method). Voila!
Reclaiming the back button #
I believe that, as more developers build web applications that make good use of DHTML, we will find tricks like this to be invaluable in maintaining the user experience. Hopefully, users will be able to depend upon the browser history to work as advertised – something we can’t often say about most web apps these days.
March 2005 • Ajax Buzz #
This wasn’t intended to be the Google Maps blog. Really. But hey, since they just released the Keyhole mode, I thought it might be worth going over the structure of the data.
Actually the integration of the Keyhole images is quite straightforward. The only things that had to change were (a) the functions that map between longitude/latitude pairs and pixel coordinates and (b) the tile URL generator.
The first of these is very simple. It would appear that the Maps team simply adhered to the coordinate system already in use by Keyhole, as it’s completely different than the Maps coordinate system. The mapping functions are as follows:
// Initialize the zoom levels.
//
var gZoomLevels = new Array();
for (var zoom = 0; zoom < 15; zoom++)
gZoomLevels[zoom] = Math.pow(2, 25 - zoom) / 360;
// Compute the longitude and latitude for a given pixel coordinate.
//
function getLngLat(pixelX, pixelY, zoom) {
return new Point(
pixelX / gZoomLevels[zoom] - 180,
180 - pixelY / gZoomLevels[zoom]
);
}
// Compute the pixel coordinate for a given longitude and latitude.
//
function getPixelPos(longitude, latitude, zoom) {
return new Point(
(longitude + 180) * gZoomLevels[zoom],
(180 - latitude) * gZoomLevels[zoom]
);
}
Nothing too surprising there. The part that seems to have people scratching their heads is the image URL format. At first glance, it appears to be a wacky series of characters with lots of ‘q, r, s, and t’. Well, there is a method to this madness. First, have a look at the de-obfuscated function below:
// Compute the URL of the tile with the given coordinates.
// (note that these coordinates are not the same as in the
// two functions above: they must be divided by the tile
// size, which is 256).
//
function tileUrl(x, y, zoom) {
var range = Math.pow(2, 17 - zoom);
// Wrap-around x coordinate.
//
if ((x < 0) || (x > range - 1)) {
x = x % range;
// The mod operator isn't quite the same on a computer as it is
// in your math class (negative isn't handled correctly).
//
if (x < 0)
x += range;
}
// Build the quadtree path, working our way down from 2^16
// to the current zoom level.
//
var Ac = "t";
for (var pow = 16; pow >= zoom; pow--) {
// Drop to the next zoom level.
//
range = range / 2;
if (y < range) {
if (x < range) {
// Upper-left quadrant.
//
Ac += "q";
} else {
// Upper-right quadrant.
//
Ac += "r";
x -= range;
}
} else {
if (x < range) {
// Lower-left quadrant.
//
Ac += "t";
y -= range;
} else {
// Lower-right quadrant.
//
Ac += "s";
x -= range;
y -= range;
}
}
}
return "http://kh.google.com/kh?" + "t=" + Ac;
}
Ok, so my comments were a bit of a giveaway. Basically, it looks like Keyhole stores its data in a quadtree structure, and the URL describes the ‘path’ through the tree to find a given tile. A quadtree, many of you may remember from your undergraduate graphics class, is a nice little structure for efficiently storing and accessing large tile arrays. It’s particularly effective when not all areas need to be stored with the same level of detail (as is clearly the case with Keyhole).
I won’t go into detail on the structure here, as others have already done a better job of explaining it (just do a Google search on ‘quadtree’). For our purposes, suffice it to say that q, r, s, and t refer to the four quadrants at each depth in the tree. Thus, a sequence of these characters uniquely identifies a tile at some depth.
Apr 2005 • Still More Maps #
I’ve always found it quite interesting how giving something a name seems to make it “real”. Case in point? AJAX. When I first [heard][adpativepath] this term, I thought to myself, “who really needs a specific term for a mishmash of technologies that’s been around for a long time?” Well, as is often the case, I misunderestimated the importance of having a mental “handle” for an otherwise complex concept. And just like LAMP, it’s not the specific technologies that are important (the ‘P’ in LAMP is heavily overloaded, just as the ‘XML’ in AJAX isn’t as important as the idea of communicating directly with the server).
I don’t know if I particularly care for the appelation – particularly the XML bit – but that no longer really matters. The name has probably stuck now that the WSJ has an article that opens with the words “Meet Ajax, the technology powerhouse.” So it’s settled, the concept has a name now.
And I believe it is a good thing that some kind of name has stuck. For some time now, I’ve found that everyone has their own ideas about what “rich” means to a web application (or if you’re more into Flash, an internet application); and it just takes too long to try and explain “it’s like the difference between Hotmail and Outlook”.
So now that we have a name, and an “AJAX” application has a specific meaning, what do we do now? Certainly there is more than one way to approach the problem. Should I use some sort of framework, or bang out all of the Javascript by hand? How should I encode my server calls? How should I handle back button support? What about URL-encoding my application’s state? There is a host of issues like these that need solutions (probably many solutions, depending upon your needs). It’s now time for us to begin gathering the existing solutions to these problems, and to build new ones, so that we can move the Web far beyond its current state.
Should be fun!
July 2005 • Google Maps Information #
Google Maps Information
I’ve been getting a slow but steady stream of requests for more information on how to work with Google Maps. I would love to respond to each of these individually, but honestly haven’t been doing much with it since I wrote my first few articles on the subject. Fortunately, I just ran across the Google Maps Mania blog. It seems to be doing a pretty good job of aggregating all of the stuff going on with Maps at the moment. I’m really quite amazed at the array of different things people are building with it (and I doubt there’s any way I could keep up with it all anyway). Happy mapping to all!